
Docker (容器) 的原理
第一次接触 docker 的人可能都会对它感到神奇,一行 docker run,就能创建出来一个类似虚拟机的隔离环境,里面的依赖都是 reproduceable 的!然而这里面并没有什么魔法,有人说 Docker 并没有发明什么新的技术。确实是,它只不过是将一些 Linux 已经有的功能集合在一起,提供了一个简单的 UI 来创建“容器”。
这篇文章用来介绍容器的原理。
什么是一个容器?我们从容器的标准开始说起。
1. OCI Specification
OCI 现在是容器的事实标准,它规定了两部分的标准:
Image spec:容器如何打包。
Runtime spec:容器如何运行。

1.1 Image Spec
容器的运行时是通过 Image 创建的,Image Spec 规定了这个 Image 里面要放什么文件。本质上,一个 Image 就是一个 tar 包。里面一般包含这些内容:
manifest 里面包含 config 和 layers,其中 config 包含以下内容的配置:
创建运行时(container)的时候需要的配置
layers的配置
image 的 metadata
layers 就是组成 rootfs 的一些文件。base 层的 layer 有所有的文件,之后的 layer 只保存基于 base 层的 changes。在创建容器的时候需要打开这个 Image,先找到 base layer,然后将之后的 layer 一个一个地 apply changes,得到最后的 rootfs。

我们可以下载一个 Nginx 的 Docker Image 来看下里面都有什么。
首先 pull 下来 docker 的 image,然后将它保存为一个 tar 文件。
然后再把它解压开:
然后使用 tree 命令看下里面的结构:
打开 manifest.json 就会发现里面标注了 config 文件,以及 layers 的信息,config 里面有每一层 layer 的信息。
如果解压 layer.tar,就可以看到里面用于构建 rootfs 的一些文件了。
容器运行的时候,就依赖这些文件,而不依赖 host 系统上的依赖。这样就做到和 host 上面的依赖隔离。
1.2 Runtime Spec
从 Image 解包之后,我们就可以创建 container 了,大体的过程就是创建一个 container 然后在 container 中运行进程。因为有了 Image 里面的依赖,容器里面就可以不依赖系统的任何依赖。
容器的生命周期如下:

1.3 Image, Container 和 Process
Containers 从 Image 创建,一个 Image 可以创建多个 contaners。
但是在 Container 作出修改之后,也可以直接将里面的内容保存为新的 Image。
进程运行在 Container 里面。
1.4 实现和生态
runC 是 OCI 的标准实现。Docker 是在之上包装了 daemon 和 cli。
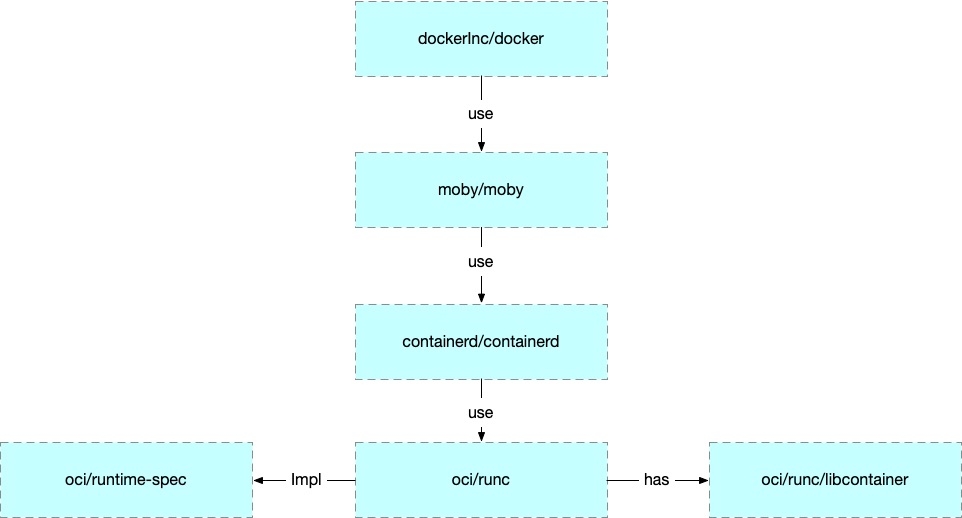
Kubernetes 为了实现可替换的容器运行时实现,定义了 CRI (Container Runtime Interface),现在的实现有 cri-containerd 和 cri-o 等,但是都是基于 oci/runc 的。

所以后文中使用 runc 来解释容器用到的一些技术。
2. 进程之间的隔离
如果没有 namepsace 的话,就不会有 docker 了。在容器里面,一个进程只能看到同一个容器下面的其他进程(pid),就是用 namespace 实现的。
namespace 有很多种,比如 pid namespace, mount namespace。先来通过例子说 pid namespace。
2.1 运行 runc
要运行一个 runc 的容器,首先需要一个符合 OCI Spec 的 bundle。我们可以直接通过 docker 创建这样的一个 bundle。
首先我们创建一个目录来运行我们的 runc,在里面需要创建一个 rootfs 目录。然后用 docker 下载一个 busybox 的 image 输出到 rootfs 中。
然后运行 runc spec ,这个命令会创建一个 config.json 作为默认的配置文件。
进入到 containers 文件夹,就可以运行 runc 了(需要 root 权限)。
2.2 查看 namespace
容器只是在 host 机器上的一个普通进程而已。我们可以通过 perf-tools 里面的 execsnoop 来查看容器进程在 host 上面的 pid。execsnoop 顾名思义,可以 snoop Linux 的 exec 调用。在虚拟机里面可能不工作,最好找一台物理机(或者笔记本)进行试验。
我们退出刚才的 runc 容器,先打开 execsnoop,然后在另一个窗口中在开启容器。会发现 host 上有了新的进程。
新的进程的 pid 是 92528.
可以使用 ps 程序查看这个 pid 的 pid namespace.
可以看到在宿主机这个进程的 pidns 是 4026534092。
这个命令只显示了 pid namespace, 我们可以通过 /proc 文件系统查看这个进程其他的 pidns.
使用 cinf 工具,可以查看这个 namespace 更详细的内容。
可以看到这个 ns 下面只有一个进程。
到这里可以得出结论,当我们启动一个新的容器的时候,一系列的 namespace 会自动创建,init 进程会被放到这个 namespace 下面:
一个级才能拿只能看到同一个 namespace 下面的其他进程
在容器里面 pid=1 的进程,在 host 上只是一个普通进程
2.3 docker/runc exec
那么当我们执行 exec 的时候发生了什么呢?
运行 runc exec xyxy /bin/top -b ,从 execsnoop 中可以看到 pid:
直接使用 runc 的 ps 命令也可以看到 pid,但是 pid 会和 execsnoop 显示的命令不一样:
在运行原来的 cinf 命令查看这个 namespace:
可以看到现在这个 namespace 下面有两个进程了。
在 runc 的容器里面我们去看 top,会发现有两个进程,它们的 pid 分别是 1 和 13,这就是 namespace 的作用。
3. cgroups
Namespaces 可以控制进程在 container 中可以看到什么(隔离),而 cgroups 可以控制进程可以使用的资源(资源)。
我们可以使用 lsgroup 查看现在系统上的 cgroup, 然后将它保存到一个文件中。
然后使用 runc run xyxy 启动一个名字叫 xyxy 的容器,再次查看 cgroup:
可以看到容器创建之后系统上多了一些 cgroup,并且它们的 parent 目录是我们的 sh 所在的 cgroup.
cgroup 可以控制进程所能使用的内存,cpu 等资源。
在容器的 cgroup 中也可以加入更多的进程。
首先使用 runc 查看一下进程的 pid:
然后查看这个 cgroup 下面有哪些进程:
发现只有这一个。
下面通过容器的 exec 命令加入一个新的进程到这个 cgroup 中:
然后再次查看是否有新的 cgroup 生成:
输出为空,说明没有新的 cgroup 生成。
然后通过查看原来的 cgroup,可以确认新的进程 top 被加入到了原来的 cgroup 中。
总结:当一个新的 container 创建的时候,容器会为每种资源创建一个 cgroup 来限制容器可以使用的资源。
那么如何通过 cgroup 来对资源限制呢?
默认情况下的容器是不限制资源的,比如说内存,默认情况下是 9223372036854771712:
要限制一个容器使用的内存大小,只需要将限制写入到这个文件里面去就可以了:
内存是一个非弹性的资源,不像是 CPU 和 IO,如果资源压力很大,程序不会直接退出,可能会运行慢一些,然后再资源缓解的时候恢复。对于内存来说,如果程序无法申请出来需要的内存的话,就会直接退出(或者 pause,取决于 memory.oom_control 的设置)。
上面这种修改 cgroup 限制的方法,其实就是 runc 在做的事情。但是使用 runc 我们不应该直接去改 cgroup,而是应该修改 config.json ,然后 runc 帮我们去配置 cgroup。
修改方法是在 linux.resources 下面添加:
然后 runc 启动之后可以查看 cgroup 限制。
我们可以验证 runc 的资源限制是通过 cgroup 来实现的,通过修改内存限制到一个很小的值(比如10000)让容器无法启动而报错:
从错误日志可以看到,cgroup 的限制文件无法写入。可以确认底层就是 cgroup。
4. Linux Capabilities
Capabilities 也是 Linux 提供的功能,可以在用户有 root 权限的同时,限制 root 使用某些权限。
先准备好一个容器,带有 Libcap,这里我们还是直接使用 docker 安装好然后导出。
然后将这个 docker 容器导出到 runc 的 rootfs:
然后进入到容器里面验证,会发现在容器里面无法修改 hostname,即使已经是 root 了也不行:
这是因为,修改 hostname 需要 CAP_SYS_ADMIN 权限,即使是 root 也需要。
我们可以将 CAP_SYS_ADMIN 加入到 init 进程的 capabilities 的 bounding permitted effective list 中。
修改 capabilities 为以下内容:
然后重新开启一个容器进去测试,发现就可以修改 hostname 了。
4.1 查看 Capability
要使用 pscap ,首先要安装 libcap-ng-utils,然后可以查看刚刚打开的那两个容器的 capabilities:
可以看到一个有 sys_admin ,一个没有。
除了修改 config.json 来添加 capabilities,也可以在 exec 的时候直接通过命令行参数 --cap 来要求 additional caps.
在容器中,可以通过 capsh 命令查看 capability:
可看到 Current 和 Bounding 里面有 cap_sys_admin。+ep 的意思是它们也在 effective 和 permitted 中。
5. 文件系统的隔离
在容器中只能看到容器里面的文件,而不能看到 host 上面的文件(不map的情况下),做到了隔离。
Linux 使用 tree 的形式组织文件系统,最底层叫做 rootfs, 一般由发行版提供,mount 到 / 。然后其他的文件系统 mount 到 / 下面。比如,可以将一个外部的 USB 设备 mount 到 /data 下面。
mount(2)是用来 mount 文件的系统的 syscall。当系统启动的时候,init 进程就会做一些初始化的 mount。
所有的进程都有自己的 mount table,但是大多数情况下都指向了同一个地方,init process 的 mount table。
但是其实可以从 parent 进程继承过来之后,再做一些改变。这样只会影响到它自己。这就是 mount namespace。如果 mount namespace 下面有任何进程修改了 mount table,其他的进程也会受到影响。所以当你在shell mount 一个 usb 设备的时候,GUI 的 file explorer 也会看到这个设备。
5.1 Mount Namespace
一般来说应用在启动的时候不会修改 mount namespace. 比如现在在我的虚拟机中,就有一下的 mount namespace:
现在启动一个 container,可以看到有了新的 mount namespace:
在 host 进程上查看 mount info:
可以看到这个进程的 / mount 到了 /dev/mapper/vagrant-root 上。
在 host 机器上,查看 mount,会发现这个设备同样 mount 在了 / 上。
所以这里就有了问题:为什么 container 的 rootfs 会和 host 的 rootfs 是一样的呢?这是否意味着 contianer 能读写 host 的文件了呢?contianer 的 rootfs 不应该是 runc 的 pwd 里面的 rootfs 吗?
我们可以看下 container 里面的 / 到底是什么。
在 container 里面查看 / 的 inode number:
然后看下 Host 上运行 runc 所在的 pwd 下面的 rootfs:
可以看到,容器里面的 / 确实就是 host 上的 rootfs。
但是他们是怎么做到都 mount 到 /dev/mapper/vagrant-root 的呢?
这里的 “jail” 其实是 privot_root 提供的。它可以改变 process 的运行时的 rootfs. 相关代码可以查看这里。这个 idea 其实来自于 lxc。
5.2 chroot
要做到文件系统的隔离,其实并不一定需要创建一个新的 mount namespace 和 privot_root 来进行文件系统的隔离,可以直接使用 chroot(2) 来 jail 容器进程。chroot 并没有改变任何 mount table,它只是让进程的 / 看起来就是一个指定的目录。
关于 chroot 和 privot_root 的对比可以参考这里。
简单来说,privot_root 更加彻底和安全。
如果在 runc 使用 chroot,只需要将 {“type”:”mount”} 删掉即可。
也可以删掉这部分,这是为 privot_root 准备的。
然后创建一个新的容器,发现依然不能读写 rootfs 之外的东西。
5.3 Bind Mount
Linux 支持 bind mount. 就是可以将一个文件目录同时 mount 到多个地方。这样,我们就可以实现在 host 和 container 之间共享文件了。
在 config.json 中作出一下修改:
这样, host 上面的 /home/vagrant/test_cap/workspace_host 就会和容器中的 /my_workspace 同步了。可以在 host 上面执行:
然后在 container 里面:
Bind 不仅可以用来 mount host 的目录,还可以用来 mount host 上面的 device file。比如可以将 host 的 UBS 设备 mount 到 container 中。
5.4 Docker Volume
Volume 是 docker 中的概念,OCI 中并没有定义。
本质上它仍然是一个 mount,可以理解为是 docker 帮你管理好这个 mount,你只要通过命令行告诉 docker 要 mount 的东西就好了。
6. User and root
User 和 permission 是 Linux 上面几乎最古老的权限系统了。工作原理简要如下:
系统有很多 users 和 groups
每个文件术语一个 owner 和一个 group
每一个进程术语一个 user 和多个 groups
结合以上三点,每一个文件都有一个 mode,标志了针对三种不同类型的进程的权限控制: owner, group 和 other.
注意 kernel 只关心 uid 和 guid,user name 和 group name 只是给用户看的。
6.1 执行容器内进程的 uid
config.json 文件中的 User 字段可以指定容器的进程以什么 uid 来运行,默认是 0,即 root。这个字段不是必须的,如果删去,依然是以 uid=0 运行。
在 host 上,uid 也是 0:
不推荐使用 root 来跑容器。但是好在默认我们的容器进程还受 capability 的限制。不像 host 的 root 一样有很多权限。
但是仍然推荐使用一个非 root 用户来运行容器的进程。通过修改 config.json 的 uid/guid 可以控制。
然后在容器中可以看到 uid 已经变成 1000 了。
在 host 上可以看到进程的 uid 已经不是 root 了:
创建容器的时候默认不会创建 user namespace。
6.2 使用 User namespace 进行 UID/GID mapping
接下来我们创建一个单独的 user namespace.
在开始之前我们先看下 host 上现有的 user namespace:
然后通过修改 config.json 来启用 user namespace. 首先在 namespaces 下面添加 user 来启用,然后添加一个 uid/guid mapping:
然后重新运行容器,再次查看 user namespace:
在容器里面,我们看到 uid=1000:
但是在 host 上,这个进程的 pid=2000:
这就是 uid/gid mapping 的作用,通过 /proc 文件也可以查看 mapping 的设置:
通过设置容器内的进程的 uid,我们就可以控制他们对于文件的权限。比如如果文件的 owner 是 root,我们可以通过设置 uid 来让容器内的进程不可读这个文件。
一般不推荐使用 root 运行容器的进程,如果一定要用的话,使用 user namespace 将它隔离出去。
在同一个容器内运行多个进程的场景中,也可以通过 user namespace 来单独控制容器内的进程。
7. 网络
在网络方面,OCI Runtime Spec 只做了创建和假如 network namespace, 其他的工作需要通过 hooks 完成,需要用户在容器的运行时的不同的阶段来进行自定义。
使用默认的 config.json ,就只有一个 loop device ,没有 eth0 ,所以也就不能连接到容器外面的网络。但是我们可以通过 netns 作为 hook 来提供网络。
首先,在宿主机上,下载 netns 到 /usr/local/bin 中。因为 hooks 在 host 中执行,所以这些 Binary 要放在 host 中而不是容器中,容器的 rootfs 不需要任何东西。
7.1 使用 netns 设置 bridge network
在 config.json 中作出如下修改,除了 hooks,还需要 CAP_NET_RAW capability, 这样我们才可以在容器中使用 ping。
然后再启动一个新的容器。
可以看到除了 loop 之外,有了一个 eth0 device.
也可以 ping 了:
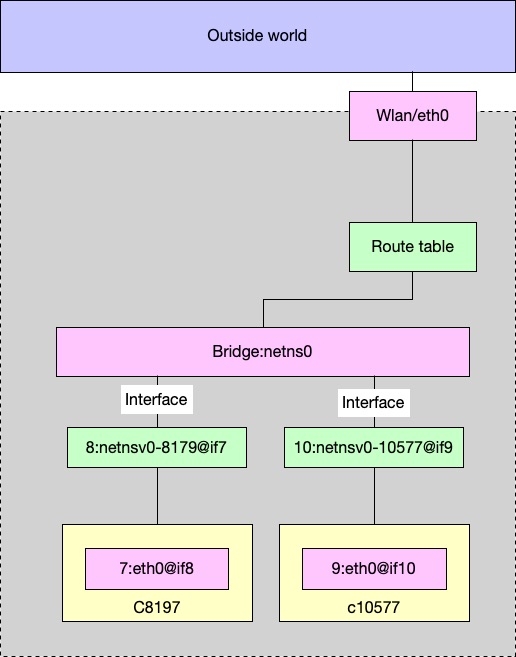
7.2 Bridge, Veth, Route and iptable/NAT
当一个 hook 创建的时候,container runtime 会将 container 的 state 传给 hook,包括 container的 pid, namespace 等。然后 hook(在这里就是 netns )就会通过这个 pid 来找到 network namespace,然后 netns 会做以下几件事:
创建一个 linux bridge,默认的名字是
netns0,并且设置MASQUERADErule;创建一个 veth pair,一端连接
netns0,另一端连接 container network namespace, 名字在 container 里面是eth0;给 container 里面的
eth0分配一个 ip,然后设置 route table.
7.2.1 bridge and interfaces
netns0 穿件的时候又两个 interfaces,名字是 netnsv0-$(containerPid):(brctl 需要通过 apt install bridge-utils 安装)
netnsv0-8179 是 veth pair 其中的一个,连接 bridge,另一个 endpoint 是 container 中的。
7.2.2 vthe pair
在 host 中,netnsv0-8179 的 index 是7:
然后在 container 中,etch0 的 index 也是7.
所以可以确认容器里面的 eth0 和 host 的 netnsv0-8179 是一对 pair。
同理可以确认 netnsv0-10577 是和 container 10577 中的 eth0 是一对 pair。
到这里我们知道容器是如何和 host 通过 veth pair 搭建 bridge 的。有了 network interfaces,还需要 route table 和 iptables.
7.2.3 Route Table
container 里面的 routing table 如下:
可以看到所有的流量都从 eth0 到 gateway, 即 bridge netns0:
在 host 上:
以及:
192.168.1.1 是 home route,一个真实的 bridge.
总结起来,ping 的时候,从 container 中,包会从 netns 的 virtual bridge netns ,发送到一个真正的 route gateway,然后到外网去。
7.2.4 iptable/nat
netns 做的另一个事情是设置 MASQUERADE,这样所有从 container 发出去的包(source是 172.19.0.0/16 )都会被 NAT,这样外面只会看到这个包是从 host 来的,而不知道是否来自于一个 container,只能看到 host 的 IP。
至此,容器用到的一些技术基本上就讲完了。所以说容器本质上是使用 Linux 提供的一些技术来实现进程的隔离,对于 host 来说,它仍然只是一个普通的进程而已。
参考资料:
主要是一些 Linux 手册,以及最主要的,Bin Chen 的博客:Understand Container. 本文基本上是我在学习他的博客的笔记。
8. 相关文章:
最后更新于