
Java 并发 - Volatile
1. 前言
在前面的文章中,我们已经了解了Java的内存模型,了解了其可见性问题及指令重排序及Happen-Before原则,现在我们来了解一下关键字volatile。在Java中volatile可以算是Java提供的轻量级同步实现机制,但是在平时开发中,我们更多的是使用synchronized来进行同步。对于volatile,大家总是不能正确的且完整的理解。所以下面,我就和大家一起来了解一下volatile。
2. volatile的作用
2.1 线程的可见性
当一个变量定义为volatile后,那么该变量对所有线程都是“可见的”,其中“可见的”是指当一条线程修改了这个变量的值,那么新值对于其他线程来说是可以立即知道的。可能大家还是不好的理解。如果你阅读过上篇文章Java并发编程之Java内存模型,你应该很快的理解。不过没有大碍,通过下列图片大家应该很快的了解。
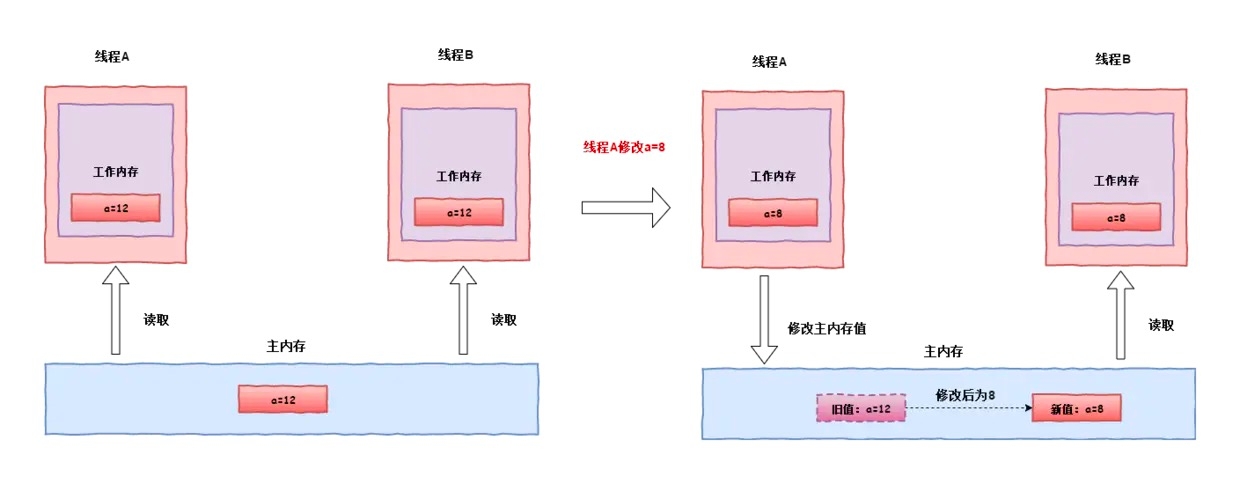
我们已经知道在Java内存模型中,内存分为了线程的工作内存及主内存。在上图中,线程A与线程B分别从主内存中获取变量a(用volatile修饰)到自己的工作内存中,也就是现在线程A与线程B中工作内存中的a现在的变量为12,当线程A修改a的值为8时,会将修改后的值(a=8)同步到主内存中,同时那么会导致线程B中的缓存a变量的值(a=12)无效,会让线程B重新重主内存中获取新的值(a=8)。
2.1.1 volatile可见性的原理
在上篇文章Java并发编程之Java内存模型中我们曾经讲过,物理计算机为了处理缓存不一致的问题。提出了缓存一致性的协议,其中缓存一致性的核心思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
既然volatile修饰的变量能具有“可见性”,那么volatile内部肯定是走的底层,同时也肯定满足缓存一致性原则。因为涉及到底层汇编,这里我们不要去了解汇编语言,我们只要知道当用volatile修饰变量时,生成的汇编指令会比普通的变量声明会多一个Lock指令。那么Lock指令会在多核处理器下会做两件事情。
将当前处理器缓存行的数据直接写会到系统内存中(从Java内存模型来理解,就是将线程中的工作内存的数据直接写入到主内存中)
这个写回内存的操作会使在其他CPU里缓存了该地址的数据无效(从Java内存模型理解,当线程A将工作内存的数据修改后(新值),同步到主内存中,那么线程B从主内存中初始的值(旧值)就无效了)
2.2 防止重排序
同样的在上篇文章Java并发编程之Java内存模型中,我们提到了为了提高CPU(处理器)的处理数据的速度,CPU(处理器)会对没有数据依赖性的指令进行重排序,但是CPU(处理器)的重排序会对多线程带来问题。具体问题我们用下列伪代码来阐述:
isInit用来标志是否已经初始化配置。其中1,2操作是没有数据依赖性,同理3、4操作也是没有数据依赖性的。那么CPU(处理器)可能对1、2操作进行重排序。对3、4操作进行重排序。现在我们加入线程A操作Init()方法,线程B操作doSomething()方法,那么我们看看重排序对多线程情况下的影响。
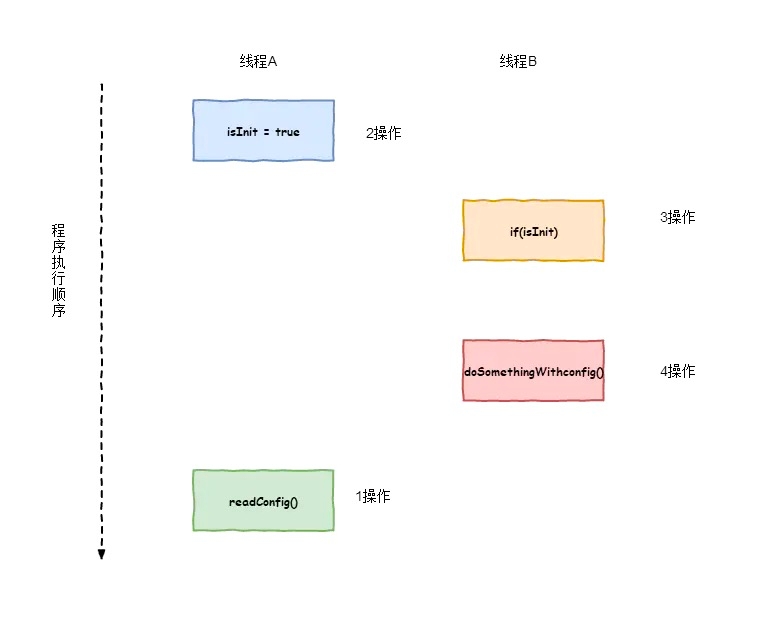
上图中2操作排在了1操作前面。当CPU时间片转到线程B。线程B判断 if (isInit)为true,接下来接着执行 doSomethingWithconfig(),但是我们Config还没有初始化。所以在多线程的情况下。重排序会影响程序的执行结果。所以为了防止重排序带来的问题。Java内存模型规定了使用volatile来修饰相应变量时,可以防止CPU(处理器)在处理指令的时候禁止重排序。具体如下图所示。
2.2.1 volatile防止重排序规则
那么为了处理CPU重排序的问题。Java定义了以下规则防止CPU的重排序。
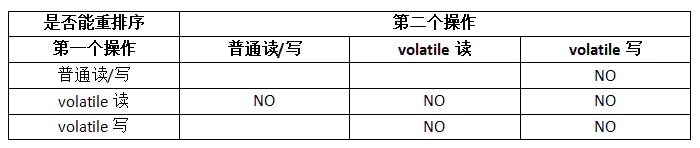
从上表我们可以看出:
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序,这个规则确保voatile写之前的操作不会被编译器排序到volatile之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作如果是volatile读或volatile写时,不能进行重排序。
2.2.2 volatile防止重排序原理
为了具体实现上诉我们提到的重排序规则,在Java中对于volatile修饰的变量,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序问题。在了解内存屏障之前,我们先复习之前的主内存与工作内存交互的8种原子操作,因为内存屏障主要是对Java内存模型的几种原子操作进行限制的。具体内存8种原子操作,如下图所示:
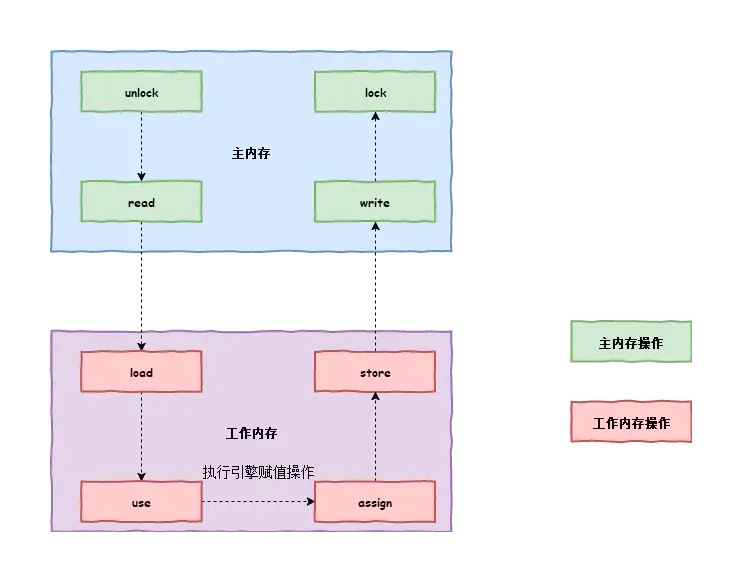
上述8中原子操作中,我们所涉及的是store与load操作,如果需要了解剩余6种操作,请参看上篇文章Java并发编程之Java内存模型。
这里对内存屏障所涉及到的两种操作进行解释:
load:作用于工作内存的变量,它把read操作从主内存中得到的变量值放入到工作内存变量副本中。store:作用于工作内存的变量,它把工作内存中一个变量值传送到主内存中。以便随后的write操作。
2.2.3 内存屏障插入策略
下面是基于volatile修饰的变量,编译器在指令序列插入的内存屏障保守插入策略如下:
在每个volatile写操作的前面插入一个storestore屏障。
在每个volatile写操作的后面插入一个storeload屏障。
在每个volatile读操作的后面插入一个loadload屏障。
在每个volatile读操作的后面插入一个loadstore屏障。
2.2.4 volatile写内存屏障
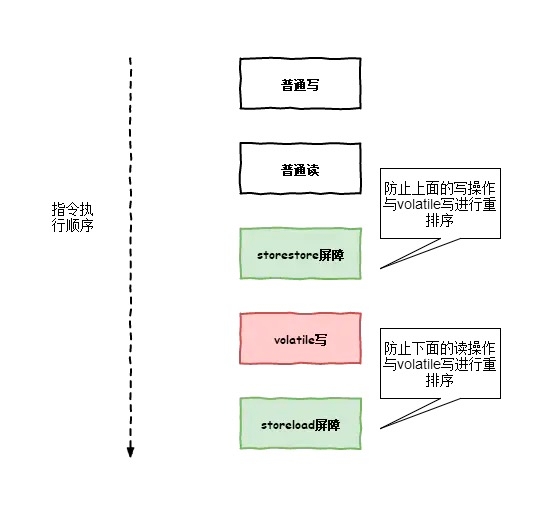
storestore屏障:对于这样的语句store1; storestore; store2,在store2及后续写入操作执行前,保证store1的写入操作对其它处理器可见。(也就是说如果出现storestore屏障,那么store1指令一定会在store2之前执行,CPU不会store1与store2进行重排序)
storeload屏障:对于这样的语句store1; storeload; load2,在load2及后续所有读取操作执行前,保证store1的写入对所有处理器可见。(也就是说如果出现storeload屏障,那么store1指令一定会在load2之前执行,CPU不会对store1与load2进行重排序)
2.2.5 volatile读内存屏障
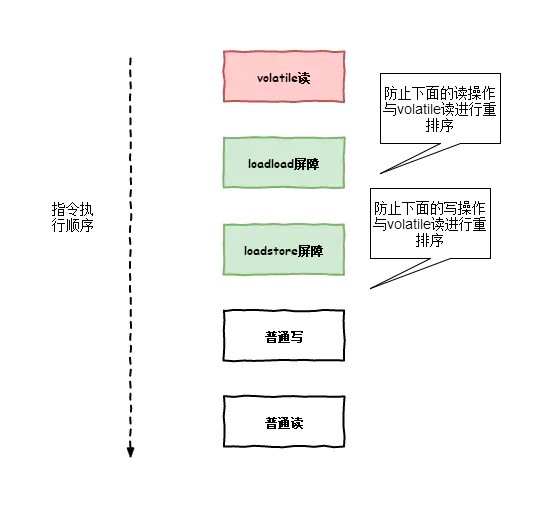
loadload屏障:对于这样的语句load1; loadload; load2,在load2及后续读取操作要读取的数据被访问前,保证load1要读取的数据被读取完毕。(也就是说,如果出现loadload屏障,那么load1指令一定会在load2之前执行,CPU不会对load1与load2进行重排序)
loadstore屏障:对于这样的语句load1; loadstore; store2,在store2及后续写入操作被刷出前,保证load1要读取的数据被读取完毕。(也就是说,如果出现loadstore屏障,那么load1指令一定会在store2之前执行,CPU不会对load1与store2进行重排序)
2.2.6 编译器内存屏障的优化
上面我们讲到了在插入内存屏障时,编译器如果采用保守策略的情况下,分别会在volatile写与volatile读插入不同的内存屏障,那现在我们来看一下,在实际开发中,编译器在使用内存屏障时的优化。
那么针对上述代码,我们生成相应的屏障(图片在手机端观看可能会不太清除,建议在pc端上观看)
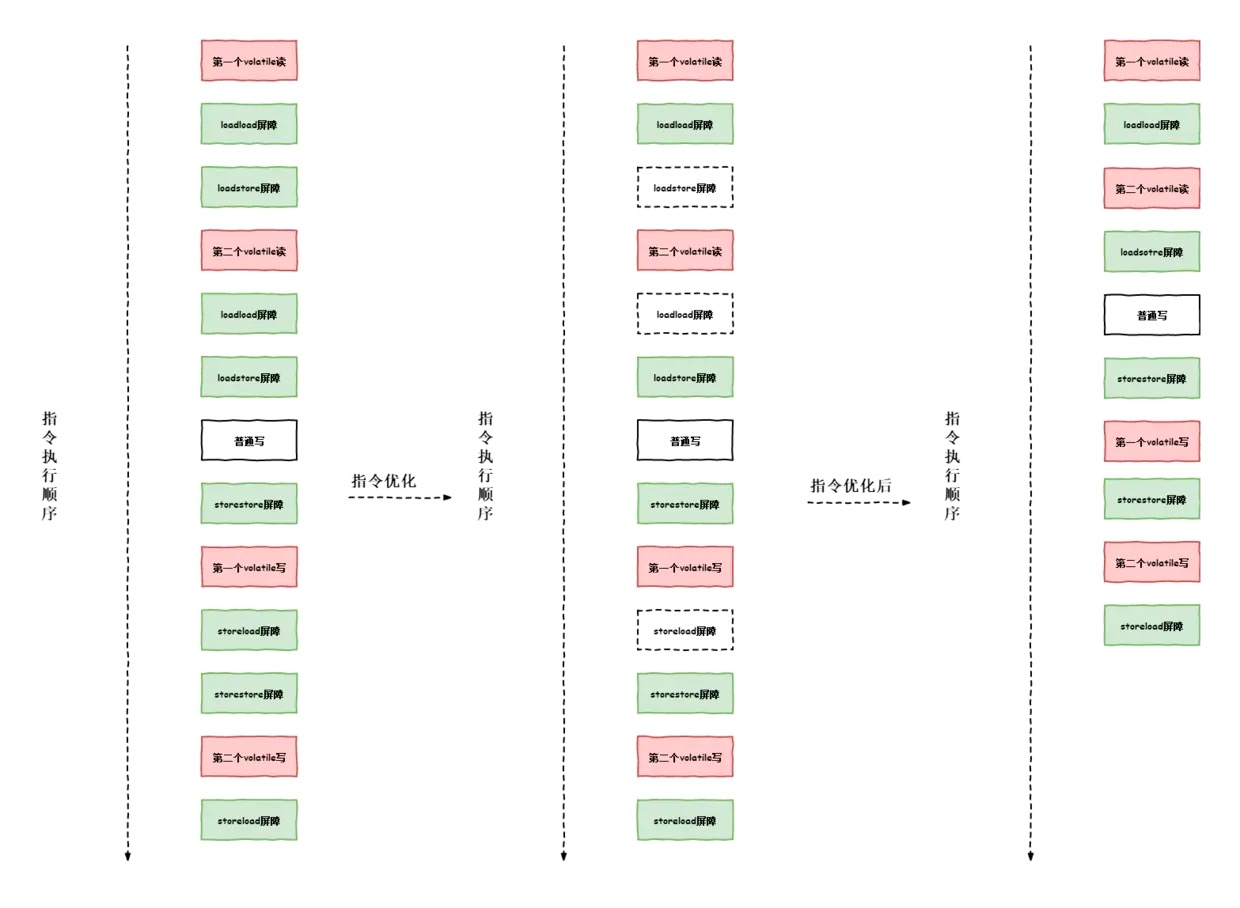
观察上图,我们发现,在编译器生成屏障时,省略了第一个volatile读下的loadstore屏障,省略了第二个volatile读下的loadload屏障,省略了第一个volatile写下的storeload屏障。结合上诉我们所讲的loadstore屏障、loadload屏障、storeload屏障下的语义,我们能得到省略以下屏障的原因。
省略第一个volatile读下的loadstore屏障:因为第一个volatile读下的下一个操作是第二个volatile的读,并不涉及到写的操作(也就是store)。所以可以省略。
省略第二个volatile读下的loadload屏障:因为第二个volatile读的下一个操作是普通写,并不涉及到读的操作(也就是load)。所以可以省略
省略第一个volatile写下的storeload屏障:因为第一个volatile写的下一个操作是第二个volatile的写,并不涉及到读的操作(也就是load)。所以可以省略。
其中大家要注意的是,优化结束后的storeload屏障时不能省略的,因为在第二个volatile写之后,方法理解return,此时编译器可能无法确定后面是否会有读写操作,为了安全起见,编译器通常会在这里加入一个storeload屏障。
2.2.7 处理器内存屏障的优化
上面我们讲了编译器在生成屏障的时候,会根据程序的逻辑操作省略不必要的内存屏障。但是由于不同的处理器有不同的“松耦度”的内存模型,内存屏障的优化根据不同的处理器有着不同的优化方式。以x86处理器为例。针对我们上面所描述的编译器内存屏障优化图。在x86处理器中,除最后的storeload屏障外,其他的屏障都会省略。
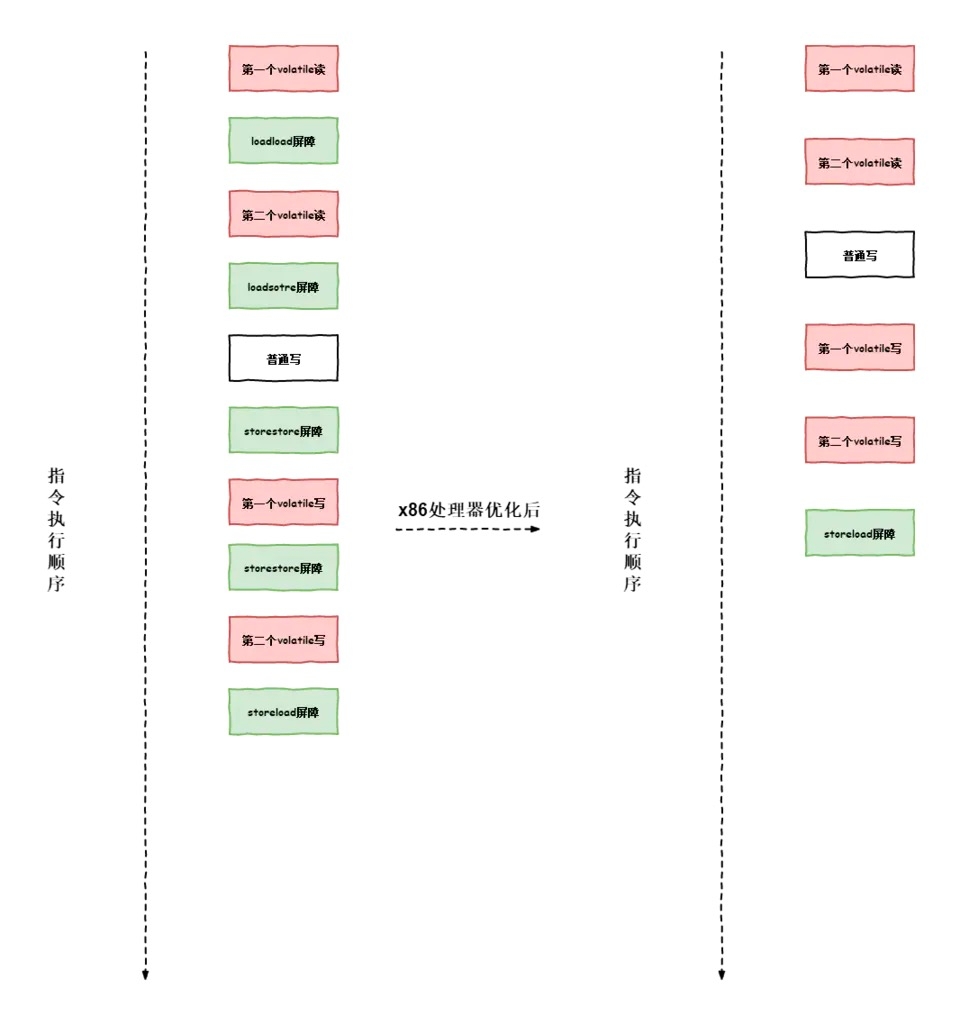
x86处理器与其他处理器的内存屏障的优化,这里不过的描述,有兴趣的小伙伴可以查阅相关资料继续研究。
3. volatile的使用注意事项
在volatile使用的时候,需要注意volatile只保证可见性,并不能保证原子性,这里所提到的原子性需要给大家补充一个知识点。
3.1 原子性定义
在Java中,对基本的数据类型的变量的访问和读写操作都是原子性操作,且这些操作在CPU中不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。
直接通过定义来理解确实比较困难,通过下面这个例子,让我们一起来了解。
大家可以来猜一猜,以上3个语句有哪些是具有原子性呢。好了。我告诉答案吧,只有语句1具有原子性。大家对此会感到很疑惑。
对于语句1:是直接将数值10赋给x,也就是直接将数值10赋值到工作内存中
对于语句2:先去读取x的值,然后计算x加上1后的值,最后将计算后的值赋值给x,
对于语句3:同语句2。
对于语句2,3因为涉及到多个操作,且在多线程的情况下,CPU可以进行时间片的切换操作(也就是可以暂停在某个操作后)。那么就可能出现线程安全的问题。
3.2 volatile为什么不具备原子性
描述了原子性后,相信大家都会有个疑问“volatile不具备原子性有什么关系呢?其实原因很简单,虽然volatile是具备可见性的(也就是指当一条线程修改了这个变量的值,那么新值对于其他线程来说是可以立即知道的),但是对于该变量有可能有多个操作例如上文提到的x++。那么在有多个操作的情况下,CPU任然可以先暂停然后在调度的。既然能被暂停后继续在调度,那么volatile肯定是不具备原子性的了。
首先需要了解的是,Java中只有对基本类型变量的赋值和读取是原子操作,如i = 1的赋值操作,但是像j = i或者i++这样的操作都不是原子操作,因为他们都进行了多次原子操作,比如先读取i的值,再将i的值赋值给j,两个原子操作加起来就不是原子操作了。
所以,如果一个变量被volatile修饰了,那么肯定可以保证每次读取这个变量值的时候得到的值是最新的,但是一旦需要对变量进行自增这样的非原子操作,就不会保证这个变量的原子性了。
举个栗子
一个变量i被volatile修饰,两个线程想对这个变量修改,都对其进行自增操作也就是i++,i++的过程可以分为三步,首先获取i的值,其次对i的值进行加1,最后将得到的新值写会到缓存中。 线程A首先得到了i的初始值100,但是还没来得及修改,就阻塞了,这时线程B开始了,它也得到了i的值,由于i的值未被修改,即使是被volatile修饰,主存的变量还没变化,那么线程B得到的值也是100,之后对其进行加1操作,得到101后,将新值写入到缓存中,再刷入主存中。根据可见性的原则,这个主存的值可以被其他线程可见。 问题来了,线程A已经读取到了i的值为100,也就是说读取的这个原子操作已经结束了,所以这个可见性来的有点晚,线程A阻塞结束后,继续将100这个值加1,得到101,再将值写到缓存,最后刷入主存,所以即便是volatile具有可见性,也不能保证对它修饰的变量具有原子性。
3.3 volatile的使用场景
现在我们已经了解了volatile的相关特性,那么就来说说,volatile的具体使用场景,因为volatie变量只能保证可见性,并不能保证原子性,所以在轻量级线程同步中我们可以使用volatile关键字。但是有两个前提条件:
第一个条件:运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
第二个条件:变量不需要与其他的状态变量共同参与不变约束。
直接理解上述两个条件,可能会有点困难,下面分别对着两个前提条件进行解释:
3.3.1 针对第一个条件
在上述伪代码中,我们能明确的看出,只要volatile修饰的变量不涉及与运算结果的依赖,那么不管是在多线程,还是单线程的情况下,都是正确的。当然我这里只是将a变量定义成成int,对于其他剩下的基础类型数据也是适用的。
3.3.2 针对第二个条件
其实理解第二个条件,大家可以反过来理解,即使用volatile的变量不能包含在其他变量的不变式中,下面伪代码将会通过反例说明:
在上述代码中,我们明显发现其中包含了一个不变式 —— 下界总是小于或等于上界(也就是lower<=upper)。那么在多线程的情况下,两个线程在同一时间使用不一致的值执行 setLower 和 setUpper 的话,则会使范围处于不一致的状态。例如,如果初始状态是(0, 5),同一时间内,线程 A 调用setLower(4) 并且线程 B 调用setUpper(3),显然这两个操作交叉存入的值是不符合条件的,那么两个线程都会通过用于保护不变式的检查,使得最后的范围值是(4, 3)。很显然这个结果是错误的。
4. 总结
volatile具有可见性不具有原子性,同时能防止指令重排序。
volatile之所以具有可见性,是因为底层中的Lock指令,该指令会将当前处理器缓存行的数据直接写会到系统内存中,且这个写回内存的操作会使在其他CPU里缓存了该地址的数据无效。
volatile之所以能防止指令重排序,是因为Java编译器对于volatile修饰的变量,会插入内存屏障。内存屏障会防止CPU处理指令的时候重排序的问题。
最后更新于