
Zookeeper - 客户端之 Curator
ZooKeeper 是一个分布式的、开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。它是集群的管理者,监视着集群中各个节点的状态,根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Curator 是 Netflix 公司开源的一套 Zookeeper 客户端框架,解决了很多 Zookeeper 客户端非常底层的细节开发工作,包括连接重连、反复注册 Watcher 和 NodeExistsException 异常等等。Curator 包含了几个包:
curator-framework:对 Zookeeper 的底层 api 的一些封装
curator-client:提供一些客户端的操作,例如重试策略等
curator-recipes:封装了一些高级特性,如:Cache 事件监听、选举、分布式锁、分布式计数器、分布式Barrier 等
1. Curator 和 zookeeper 的版本问题
目前 Curator 有 2.x.x 和 3.x.x 两个系列的版本,支持不同版本的 Zookeeper。其中Curator 2.x.x 兼容 Zookeeper的 3.4.x 和 3.5.x。而 Curator 3.x.x 只兼容 Zookeeper 3.5.x,并且提供了一些诸如动态重新配置、watch删除等新特性。
Curator 2.x.x - compatible with both ZooKeeper 3.4.x and ZooKeeper 3.5.x
Curator 3.x.x - compatible only with ZooKeeper 3.5.x and includes support for new如果跨版本会有兼容性问题,很有可能导致节点操作失败,当时在使用的时候就踩了这个坑,抛了如下的异常:
KeeperErrorCode = Unimplemented for /***2. Curator API
这里就不对比与原生 API 的区别了,Curator 的 API 直接通过 org.apache.curator.framework.CuratorFramework 接口来看,并结合相应的案例进行使用,以备后用。
为了可以直观的看到 Zookeeper 的节点信息,可以考虑弄一个 zk 的管控界面,常见的有 zkui 和 zkweb。
zkweb:github.com/zhitom/zkwe…
我用的 zkweb ,虽然界面上看起来没有 zkui 精简,但是在层次展示和一些细节上感觉比 zkui 好一点
3. 环境准备
之前写的一个在 Linux 上安装部署 Zookeeper 的笔记,其他操作系统请自行谷歌教程吧。
本文案例工程已经同步到了 github,传送门。
PS : 目前还没有看过Curator的具体源码,所以不会涉及到任何源码解析、实现原理的东西;本篇主要是实际使用时的一些记录,以备后用。如果文中错误之处,希望各位指出。
4. Curator 客户端的初始化和初始化时机
在实际的工程中,Zookeeper 客户端的初始化会在程序启动期间完成。
4.1 初始化时机
在 Spring 或者 SpringBoot 工程中最常见的就是绑定到容器启动的生命周期或者应用启动的生命周期中:
监听 ContextRefreshedEvent 事件,在容器刷新完成之后初始化 Zookeeper
监听 ApplicationReadyEvent/ApplicationStartedEvent 事件,初始化 Zookeeper 客户端
除了上面的方式之外,还有一种常见的是绑定到 bean 的生命周期中
实现 InitializingBean 接口 ,在 afterPropertiesSet 中完成 Zookeeper 客户端初始化
关于 SpringBoot中的事件机制可以参考之前写过的一篇文章:SpringBoot-SpringBoot中的事件机制。
4.2 Curator 初始化
这里使用 InitializingBean 的这种方式,代码如下:
glmapper.zookeeper.xxx 是本例中需要在配置文件中配置的 zookeeper 的一些参数,参数解释如下:
baseSleepTimeMs:重试之间等待的初始时间
maxRetries:最大重试次数
connectString:要连接的服务器列表
sessionTimeoutMs:session 超时时间
connectionTimeoutMs:连接超时时间
另外,Curator 客户端初始化时还需要指定重试策略,RetryPolicy 接口是 Curator 中重试连接(当zookeeper失去连接时使用)策略的顶级接口,其类继承体系如下图所示:
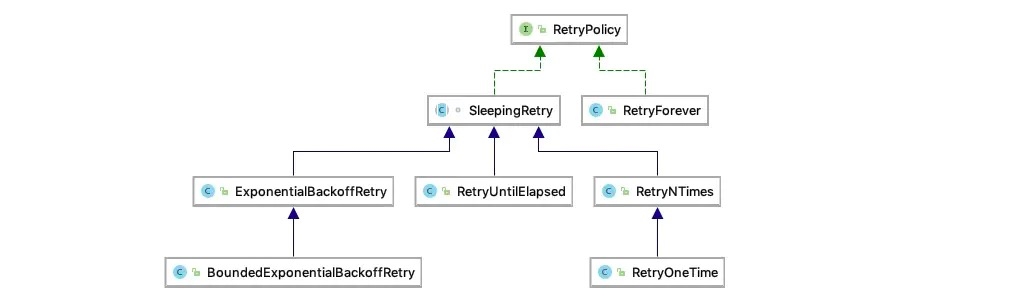
RetryOneTime:只重连一次
RetryNTime:指定重连的次数N
RetryUtilElapsed:指定最大重连超时时间和重连时间间隔,间歇性重连直到超时或者链接成功
ExponentialBackoffRetry:基于 "backoff"方式重连,和 RetryUtilElapsed 的区别是重连的时间间隔是动态的。
BoundedExponentialBackoffRetry: 同 ExponentialBackoffRetry的区别是增加了最大重试次数的控制
除上述之外,在一些场景中,需要对不同的业务进行隔离,这种情况下,可以通过设置 namespace 来解决,namespace 实际上就是指定zookeeper的根路径,设置之后,后面的所有操作都会基于该根目录。
5. Curator 基础 API 使用
5.1 检查节点是否存在
checkExists 方法返回的是一个 ExistsBuilder 构造器,这个构建器将返回一个 Stat 对象,就像调用了 org.apache.zookeeper.ZooKeeper.exists()一样。null 表示它不存在,而实际的 Stat 对象表示存在。
建议在实际的应用中,操作节点时对所需操作的节点进行 checkExists。
5.2 新增节点
非递归方式创建节点
先创建/glmapper,然后再在/glmapper 下面创建 /test ,如果直接使用 /glmapper/test 没有先创建 /glmapper 时,会抛出异常:
如果需要在创建节点时指定节点中数据,则可以这样:
指定节点类型(EPHEMERAL 临时节点)
递归方式创建节点 递归方式创建节点有两个方法,creatingParentsIfNeeded 和 creatingParentContainersIfNeeded。在新版本的 zookeeper 这两个递归创建方法会有区别; creatingParentContainersIfNeeded() 以容器模式递归创建节点,如果旧版本 zookeeper,此方法等于creatingParentsIfNeeded()。 在非递归方式情况下,如果直接创建 /glmapper/test 会报错,那么在递归的方式下则是可以的:
在递归调用中,如果不指定 CreateMode,则默认
PERSISTENT,如果指定为临时节点,则最终节点会是临时节点,父节点仍旧是PERSISTENT
5.3 删除节点
非递归删除节点
指定具体版本
使用 guaranteed 方式删除,guaranteed 会保证在session有效的情况下,后台持续进行该节点的删除操作,直到删除掉:
递归删除当前节点及其子节点
5.4 获取节点数据
获取节点数据
根据配置的压缩提供程序对数据进行解压缩处理:
读取数据并获得Stat信息:
5.5 更新节点数据
设置指定值:
设置数据并使用配置的压缩提供程序压缩数据:
设置数据,并指定版本:
5.6 获取子列表
6. 事件
Curator 也对 Zookeeper 典型场景之事件监听进行封装,这部分能力实在 curator-recipes 包下的。
6.1 事件类型
在使用不同的方法时会有不同的事件发生:
6.2 事件监听
6.2.1 一次性监听方式:Watcher
利用 Watcher 来对节点进行监听操作,可以典型业务场景需要使用可考虑,但一般情况不推荐使用。
上面这段代码对 /glmapper/test 节点注册了一个 Watcher 监听事件,并且返回当前节点的内容。后面进行两次数据变更,实际上第二次变更时,监听已经失效,无法再次获得节点变动事件了。测试中控制台输出的信息如下:
6.2.2 CuratorListener 方式
CuratorListener 监听,此监听主要针对 background 通知和错误通知。使用此监听器之后,调用inBackground 方法会异步获得监听,对于节点的创建或修改则不会触发监听事件。
测试中控制台输出的信息如下:
这里只触发了一次监听回调,就是 getData 。
6.2.3 Curator 引入的 Cache 事件监听机制
Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一个本地缓存视图与远程 Zookeeper 视图的对比过程。Cache 提供了反复注册的功能。Cache 分为两类注册类型:节点监听和子节点监听。
NodeCache
监听数据节点本身的变化。对节点的监听需要配合回调函数来进行处理接收到监听事件之后的业务处理。NodeCache 通过 NodeCacheListener 来完成后续处理。
注意:在测试过程中,nodeCache.start(),NodeCache 在先后多次修改监听节点的内容时,出现了丢失事件现象,在用例执行的5次中,仅一次监听到了全部事件;如果 nodeCache.start(true),NodeCache 在先后多次修改监听节点的内容时,不会出现丢失现象。
NodeCache不仅可以监听节点内容变化,还可以监听指定节点是否存在。如果原本节点不存在,那么Cache就会在节点被创建时触发监听事件,如果该节点被删除,就无法再触发监听事件。
PathChildrenCache
PathChildrenCache 不会对二级子节点进行监听,只会对子节点进行监听。
注意:在测试过程中发现,如果连续两个操作之间不进行一定时间的间隔,会导致无法监听到下一次事件。因此只会监听子节点,所以对二级子节点 /second 下面的操作是监听不到的。测试中控制台输出的信息如下:
TreeCache
TreeCache 使用一个内部类TreeNode来维护这个一个树结构。并将这个树结构与ZK节点进行了映射。所以TreeCache 可以监听当前节点下所有节点的事件。
测试中控制台输出的信息如下:
7. 事务操作
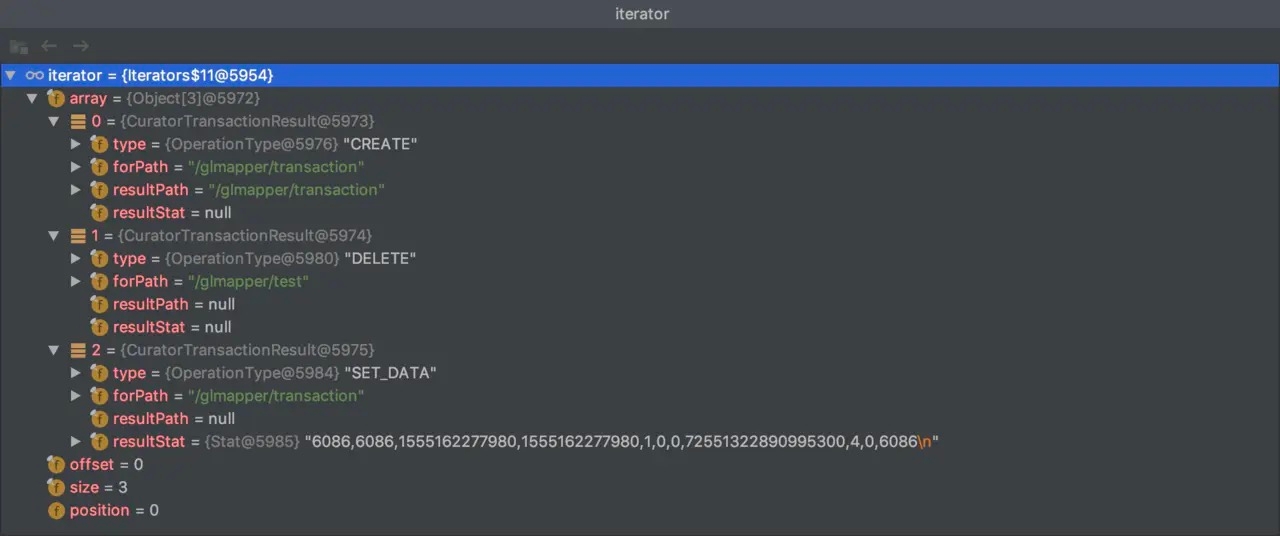
CuratorFramework 的实例包含 inTransaction( ) 接口方法,调用此方法开启一个 ZooKeeper 事务。 可以复合create、 setData、 check、and/or delete 等操作然后调用 commit() 作为一个原子操作提交。
这里debug看了下Collection信息,面板如下:
8. 异步操作
前面提到的增删改查都是同步的,但是 Curator 也提供了异步接口,引入了 BackgroundCallback 接口用于处理异步接口调用之后服务端返回的结果信息。BackgroundCallback 接口中一个重要的回调值为 CuratorEvent,里面包含事件类型、响应吗和节点的详细信息。
在使用上也是非常简单的,只需要带上 inBackground() 就行,如下:
通过查看 inBackground 方法定义可以看到,inBackground 支持自定义线程池来处理返回结果之后的业务逻辑。
这里就不贴代码了。
9. 小结
本文主要围绕 Curator 的基本 API 进行了学习记录,对于原理及源码部分没有涉及。这部分如果有时间在慢慢研究吧。另外像分布式锁、分布式自增序列等实现停留在理论阶段,没有实践,不敢妄论,用到再码吧。
10. 参考
最后更新于