
Spark SQL JOIN操作
1. 数据准备
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")emp 员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金2. 连接类型

2.1 INNER JOIN
2.2 FULL OUTER JOIN
2.3 LEFT OUTER JOIN
2.4 RIGHT OUTER JOIN
2.5 LEFT SEMI JOIN
2.6 LEFT ANTI JOIN
2.7 CROSS JOIN
2.8 NATURAL JOIN

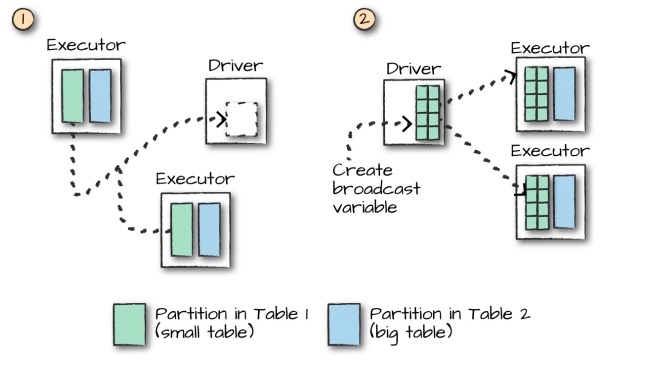
3. 连接的执行

4. 参考资料
最后更新于