
Hive常用DDL操作
1. Database
1.1 查看数据列表
show databases;
1.2 使用数据库
1.3 新建数据库
1.4 查看数据库信息
1.5 删除数据库
2. 创建表
2.1 建表语法
2.2 内部表
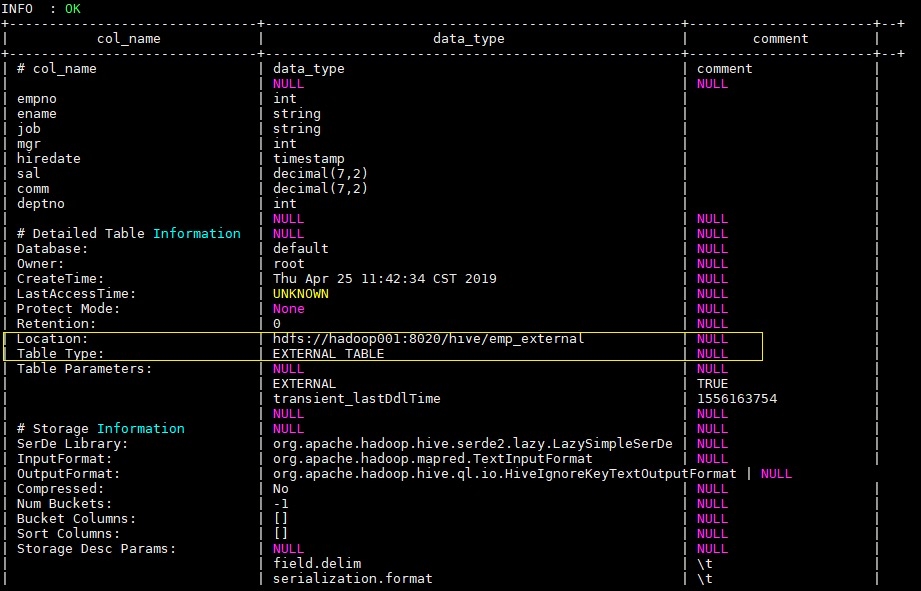
2.3 外部表
2.4 分区表
2.5 分桶表
2.6 倾斜表
2.7 临时表
2.8 CTAS创建表
2.9 复制表结构
2.10 加载数据到表

3. 修改表
3.1 重命名表
3.2 修改列
3.3 新增列
4. 清空表/删除表
4.1 清空表
4.2 删除表
5. 其他命令
5.1 Describe
5.2 Show
6. 参考资料
最后更新于