
Storm集群环境搭建
1. 集群规划

2. 前置条件
3. 集群搭建
3.1 下载并解压
3.2 配置环境变量
3.3 集群配置
3.4 安装包分发
4. 启动集群
4.1 启动ZooKeeper集群
4.2 启动Storm集群
4.3 查看集群

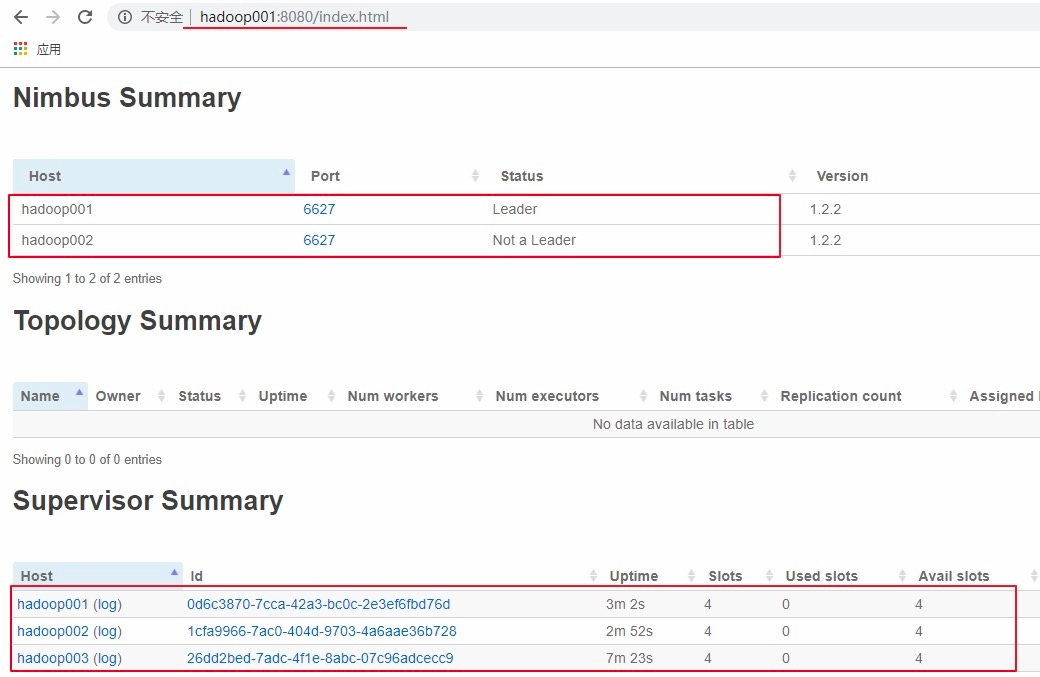
5. 高可用验证

最后更新于