
HBase的 SQL 中间层Phoenix
1. Phoenix简介

2. Phoenix安装
2.1 下载并解压
2.2 拷贝Jar包
2.3 重启 Region Servers
2.4 启动Phoenix
2.5 启动结果
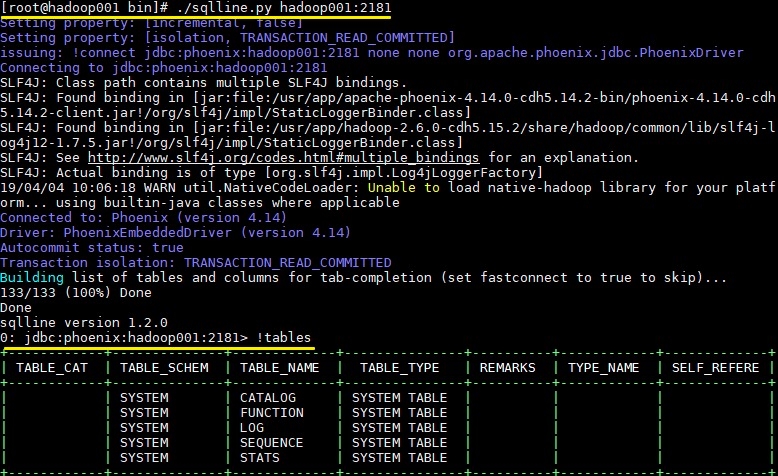
3. Phoenix 简单使用
3.1 创建表
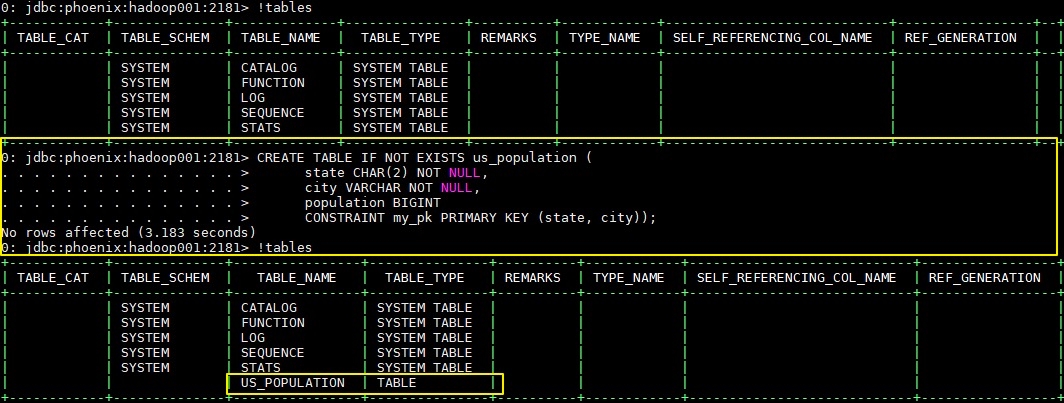
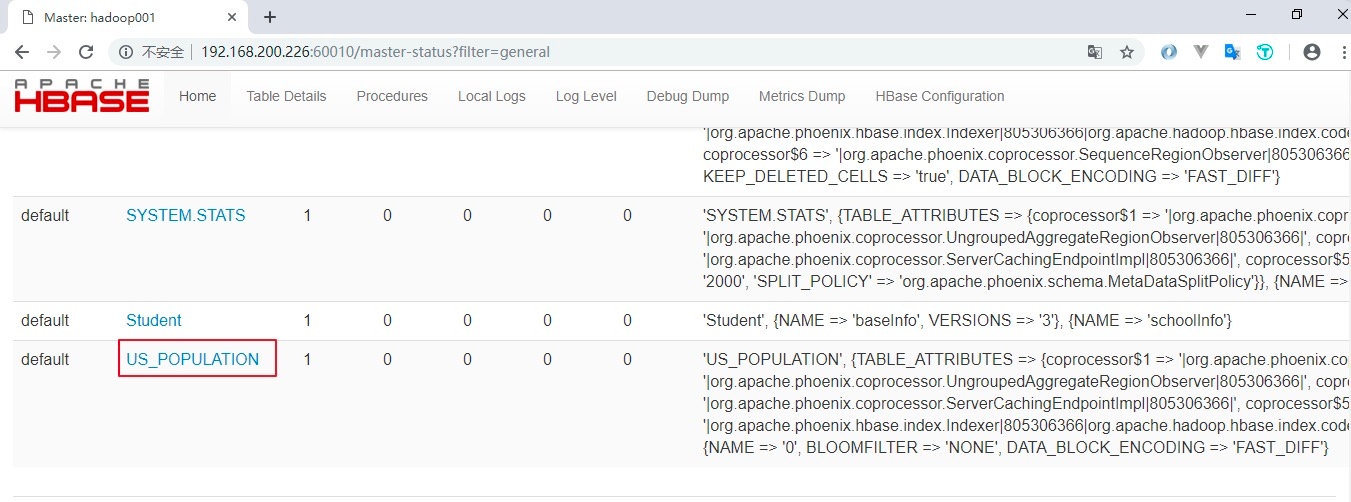
3.2 插入数据
3.3 修改数据

3.4 删除数据

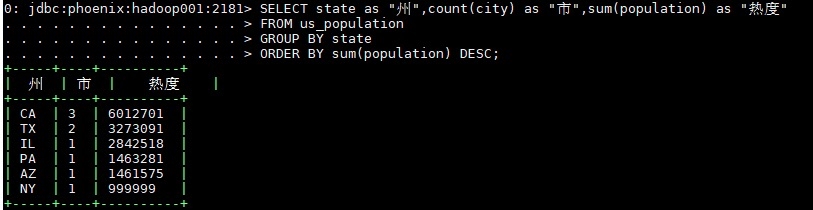
3.5 查询数据
3.6 退出命令
3.7 扩展
4. Phoenix Java API
4.1 引入Phoenix core JAR包
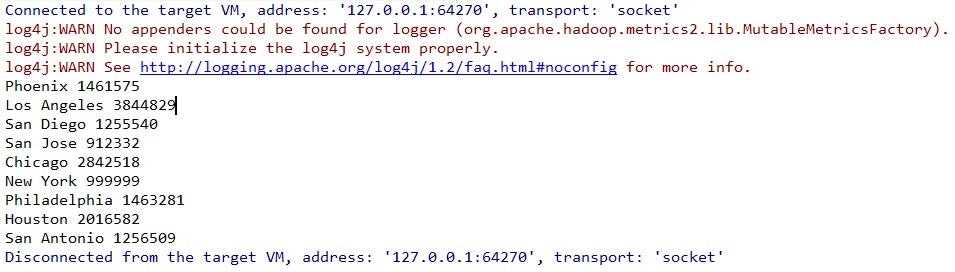
4.2 简单的Java API实例
5. 参考资料
最后更新于