
Hadoop集群环境搭建
1. 集群规划

2. 前置条件
3. 配置免密登录
3.1 生成密匙
3.2 免密登录
3.3 验证免密登录
4. 集群搭建
4.1 下载并解压
4.2 配置环境变量
4.3 修改配置
4.3.1 hadoop-env.sh
4.3.2 core-site.xml
4.3.3 hdfs-site.xml
4.3.4 yarn-site.xml
4.3.5 mapred-site.xml
4.3.6 slaves
4.4 分发程序
4.5 初始化
4.6 启动集群
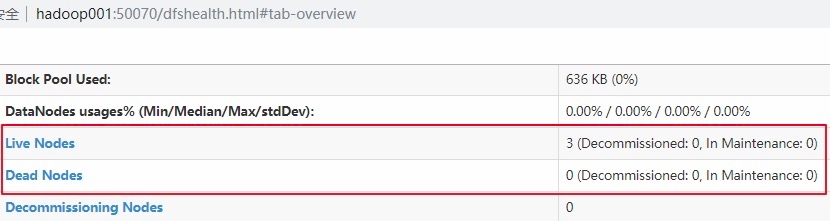
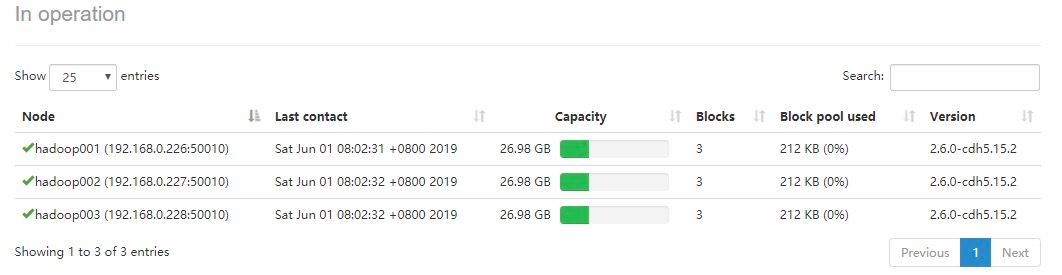
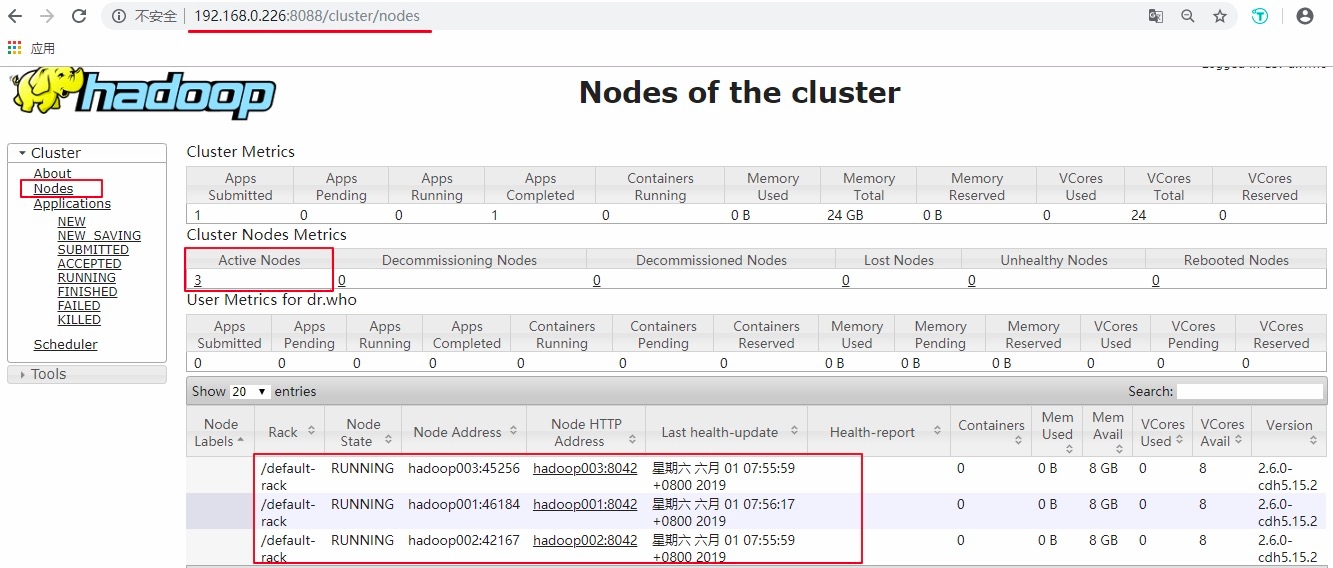
4.7 查看集群
5. 提交服务到集群
最后更新于